今天网上冲浪时看到这个网站 https://csstracking.dev/ ,提到一种使用CSS技术实现用户信息追踪的方案,挺有意思的。作者 OliverBrotchie,项目地址 https://github.com/OliverBrotchie/CSS-Fingerprint,这是一个基于 CSS 的指纹识别和纯 CSS ‘supercookie’ 的实验项目。
项目介绍了几种追踪方式和这么做的原因。简单总结就是利用浏览器加载CSS的机制,将数据信息通过接口发送给服务端,从而达到绕过现有常见的反追踪策略。具体的细节可以往下看。
使用 Media Query 追踪设备特征
利用CSS的媒体查询,针对一些特定的浏览器特性,为网站设置不同的样式。当用户访问站点时,浏览器将选择一组适用于自身的样式。可以利用这个机制,使用background-image属性将浏览器的信息发送给服务端。然后服务器将响应 HTTP 状态 410 (Gone) 以避免在后续重新加载时对这些特征的发起请求。
是不是有点意思?举一个简单的例子,检测用户设备是否有定点装置(如鼠标),以及如果有,精度如何。
// 默认没有定点装置
.pointer {
background-image: url('/some/url/pointer=none');
}
// 至少有一个输入途径包含一个精度有限的定点装置,比如触摸屏
@media (any-pointer: coarse) {
.pointer {
background-image: url('/some/url/pointer=coarse');
}
}
// fine 至少有一个输入途径包含一个精确的定点装置。比如鼠标。
@media (any-pointer: fine) {
.pointer {
background-image: url('/some/url/pointer=fine');
}
}使用font-face检测字体安装
通过类似的方式,在用户访问站点时,还能检测到安装的Web字体。
@font-face {
font-family: 'some-font';
src: local(some font), url('some/url/some-font');
}
.some-font {
font-family:'some-font';
view raw;
}如果用户的设备上没有安装对应的字体,浏览器会向CSS样式中设置的url地址发起字体下载的请求。如此一来便能知晓用户安装的字体。
https://github.com/OliverBrotchie/CSS-Fingerprint/issues/2 网友 Leland 提出这种方式在Webkit中无效。他在 Chrome 96 中测试过,
local()只对本地的系统字体有效。
利用重定向创造 CSS Cookies
假设用户的CSS中有类似前文中提到的使用url的属性。当用户访问站点时,浏览器会向对应的地址发起HTTP请求。此时,服务端响应状态码返回308永久重定向到一个唯一的地址。之后浏览器任何时候访问这个资源时,请求都会重定向到这个唯一的地址。
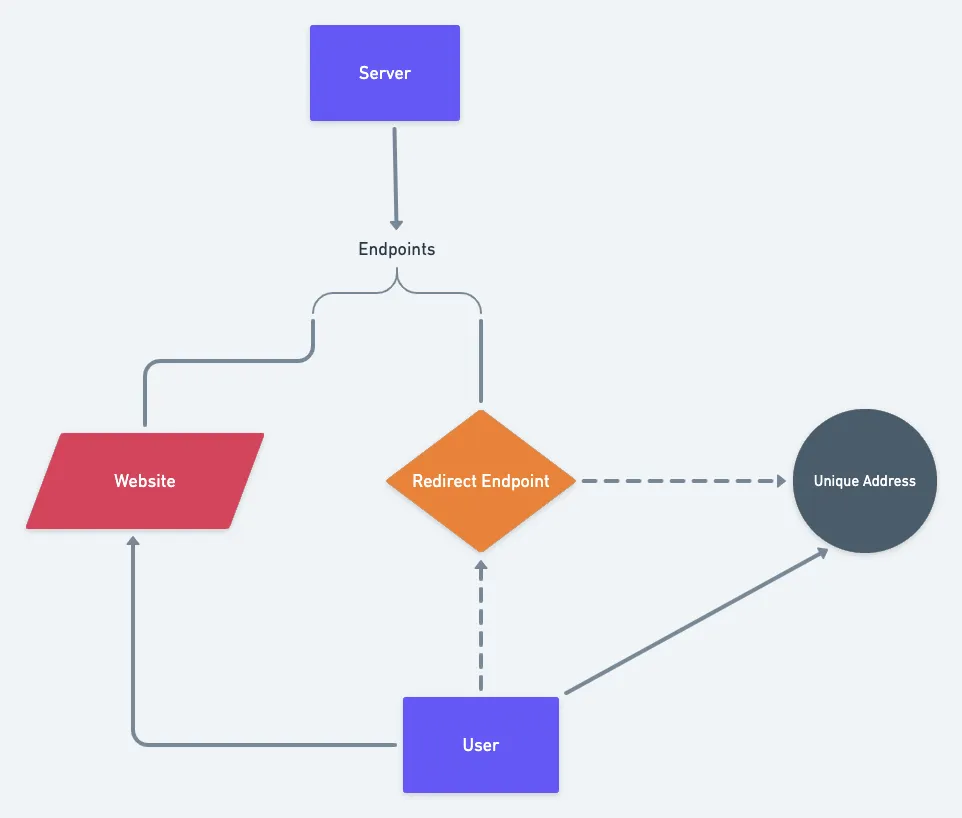
整个过程最关键的是站点的CSS属性,而最后呈现的效果就像Cookie一样,所以成之为”CSS Cookies”。只有彻底清除浏览器缓存才能干掉这个“Cookie”。
为什么要用CSS来追踪用户?
通常网站使用Cookies来实现用户追踪。但是很容易就被拦截,比如停用JavaScript或者使用浏览器插件阻止。CSS的方案可以巧妙的绕过这些阻碍。因为整个过程中都没有用到JavaScript或者Cookie。
目前这种方案的拓展性还是不够强,因为开发者需要定制大量的样式,浏览器需要下载更多CSS,发送更多请求。不过在 CSS 4 的草案中,CSS 的属性值支持变量计算。利用变量计算动态创建url的值,可以大幅降低请求的数量。
.body {
--unique-identifier: 'foo' // unique generated ID
--pointer: 'none'
--theme-preference: 'none'
// Only make one request
background-image: url("/some/url/?" + var(--unique-identifier) + "&" + var(--pointer) + "&" + var(--theme-preference))
}
// Detect pointer type and theme
@media (any-pointer: coarse){
body {
--pointer: 'coarse'
}
}
@media (prefers-color-scheme: dark) {
body {
--theme-preference: 'dark'
}
}利用草案提到的能力,不但可以提高这种方法的可扩展性,而且还将提高其精度。 目前很难将每个请求关联到某一个特定的访问用户,因为确定其来源的唯一可行方法是按照来源IP 地址对请求进行分组。 使用新草案,通过生成随机字符串并将其插入到每个访问者的 URL 标记中,可以准确地识别来自该访问者的所有请求。
不得不说这种思路很巧妙。不过也许有人质疑这种方式是否道德,正如A fundamental question #3,虽然目前各大浏览器厂商都没有限制这种方式。除了道理问题之外,还有安全问题。如果站点引用的包含恶意代码的第三方CSS文件,恶意代码可以通过这种方式收集信息,甚至发起XSS攻击。
项目作者说自己创建这个项目主要是用于研究,同时希望能够让这个问题被更多人关注。截至到目前为止(2022年1月26日),作者称曾将这个问题反馈给 Firefox 和 Chromium,但是目前没有任何举措来解决这个问题。而W3C那边的答复是用户无法选择是否运行CSS,CSS 本质上是不安全的,不应该执行不受信任的CSS样式。
延伸:如何确保资源是受信任的?
如果用户无法决定是否运行CSS,那应该如何保证加载的CSS是受信任的呢?可以使用 **内容安全策略(Content Security Policy)**来限制站点加载的资源。
CSP 是一个额外的安全层,用于检测并削弱某些特定类型的攻击,包括跨站脚本和数据注入攻击等。无论是数据盗取、网站内容污染还是散发恶意软件,这些攻击都是主要的手段。
CSP 通过告诉浏览器一系列规则,严格规定页面中哪些资源允许有哪些来源, 不在指定范围内的统统拒绝。作为一种终极防护形式,CSP甚至可以在禁止JavaScript执行。
实施有两种途径:
- 服务器添加
Content-Security-Policy响应头来指定规则 - HTML 中添加 标签来指定
Content-Security-Policy规则
常见案例
- 想要所有内容均来自站点的同一个源 (不包括其子域名)
Content-Security-Policy: default-src 'self'- 允许内容来自信任的域名及其子域名 (域名不必须与CSP设置所在的域名相同)
Content-Security-Policy: default-src 'self' *.trusted.com- 允许网页应用的用户在他们自己的内容中包含来自任何源的图片, 但是限制音频或视频需从信任的资源提供者(获得),所有脚本必须从特定主机服务器获取可信的代码.
Content-Security-Policy: default-src 'self'; img-src *; media-src media1.com media2.com; script-src userscripts.example.com延伸:supercookies
从这个项目中顺藤摸瓜发现了https://github.com/jonasstrehle/supercookie,利用favicon 为用户分配一个唯一的身份信息。这个项目同样也是用于教学和研究(可能国外对用户信息比较敏感的关系?)。具体细节可以参阅:https://supercookie.me/workwise
结束语
使用CSS来追踪用户的确是一个有创意的想法,但是随之而来会带来道德问题和安全问题。这种追踪方案的整个过程都是全自动的。每当对应的CSS执行,数据就会上报到服务端。如果利用JavaScript 增加一个用户确认的步骤,选择性加载CSS,那么在用户禁用 JavaScript 的情况下将无法上报数据。对应延伸出的安全问题,其实是由来已久的问题,可以通过CSP的手段来加固我们的站点。